

Stream On with Pravega
On stage: Pravega
Stream processing is at the spotlight in the space of data analytics, and the reason is rather evident: there is high value in producing insights over continuously generated data shortly rather than wait for it to accumulate and process in a batch. Low latency from ingestion to result is one of the key advantages that stream processing technology offers to its various application domains. In some scenarios, low latency is not only desirable but strictly necessary to guarantee a correct behavior; it makes little sense to wait hours to process a fire alarm or a gas leak event in the Internet of Things.
A typical application to process stream data has a few core components. It has a source that produces events, messages, data samples, which are typically small in size, from hundreds of bytes to a few kilobytes. The source does not have to be a single element, and it can be multiple sensors, mobile terminals, users or servers. . This data is ultimately fed into a stream processor that crunches it and produces intermediate or final output. The final output can have various forms, often being persisted in some data store for consumption (e.g., queries against a data set).
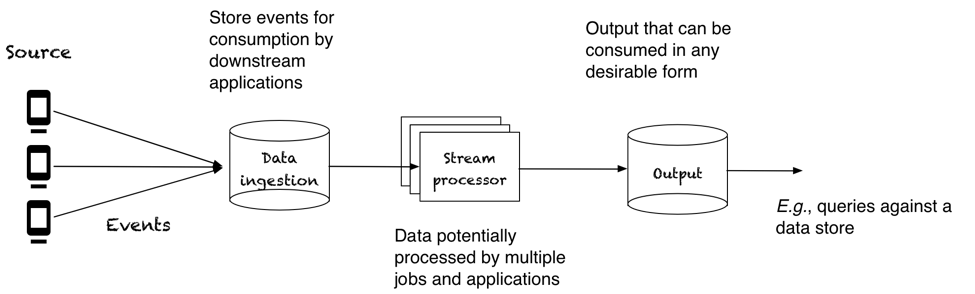
This generic architecture has storage in two parts: ingestion and output. The storage component for ingestion decouples the generation of data from the processing. Decoupling source and processing is important because different applications need to work on the same data but process the data at different speeds. For some of these applications, it is a requirement that they react fast to recent data, which imposes a requirement of low latency on the storage component from ingestion to serving. The writes to the storage are typically small, e.g., small sample events from sensors and applications read written items individually.
When reading continuously generated data from the storage component, there is a strong spatial component as applications read items sequentially. In addition to this spatial dimension, however, there is also the temporal dimension, which is not entirely emphasized by existing systems. Applications might want to process the same data at different times for various reasons, e.g., after a bug fix, when joining fresh data and historical data, or simply when processing later on a large batch of accumulated data. A storage component that provides this ability to consume continuously generated data both shortly after ingestion and much later at high-throughput for historical processing is the primary focus of this work.
Pravega is a storage system that has stream as a first-class concept. Pravega enables applications to ingest data continuously and process such stream of data either in order (following the ingestion order) or in batches (reading data in parallel, without necessarily following the stream order). Pravega offers a number of very desirable features for stream processing: low latency, stream elasticity, unbounded streams, and transactions.
At its core, Pravega uses a simple but powerful concept: segments. Segments are append-only byte sequences; they can be composed in a number of ways to form streams and to enable robust features, such as transactions and stream scaling. Pravega is ultimately a data store of segments with a control plane that tracks and manipulates these segments on behalf of applications to form streams.
In this post, we explain some core concepts of Pravega and how we think it will change the way we process stream data. We have been developing Pravega for over a year. We have recently made it open source and released our first alpha version: Pravega 0.1. In addition to being able to do the bread and butter, which is to append and read, this early version contains a few exciting features:
- Durable writes: Appends to Pravega are made durable before acknowledgment, and that’s it; there is no configurable option to relax durability. We have opted for this path because strong durability is necessary for some of the other properties we want to provide, such as order and exactly once. With this choice, the challenge the developers of Pravega have in their hands is to satisfy this guarantee while matching expected performance. Who knows – we will have to relax it in the future, but for the time being, we will stick to this choice.
- Stream scaling: Stream scaling is an impressive feature, it enables the degree of parallelism to grow and shrink automatically according to the write traffic. Of course, we allow the user to scale manually too, but it is just way more comfortable to sit back and watch Pravega do it for you.
- Transactions: Stream writers can atomically append to a Pravega stream by beginning a transaction and appending in the context of that transaction. The data appended in the context of the transaction only becomes visible in the case the transaction commits.
- State synchronizer: The state synchronizer decouples the log replication from the state replication. It enables the implementation of any replicated state machine on top of a Pravega segment. For example, one can implement leader election or group membership on top of a Pravega segment. This is really for the fanatics like myself.
There are more a few more exciting features coming up in the next release, like signaling to enable dynamic scaling downstream and data retention. External contributions are very welcome as it is part of our strategy and effort to build a community around Pravega. This page in our main website provides guidance on how to get started with Pravega.
Before Pravega
In the early days of the Big Data boom, when MapReduce was the cool kid on the block, the primary goal was to process extensive datasets fast, using clusters often comprising a few thousands of servers. Such a computation running over one or more large data sets is typically referred to as a batch job. Batch jobs enabled various applications to obtain insights out of raw data, which was very important for a number of growing companies in the online Web space. For example, in companies like Yahoo!, where a lot of the early Hadoop work has happened, there were many production jobs used for Web search, targeted advertising, recommendation, and other applications.
A batch job over a large data set typically has completion times of several minutes in the very best case, going to multiple hours depending on size and complexity of the job. Such a long delay was not ideal for a number of applications, and soon enough we started observing a desire to process data as it comes in rather than waiting to accumulate large chunks and only then process the data. For example, when doing target advertising on the Web, it is not desirable to wait for hours or days to gain any insight on the data. The same holds for any system that needs to perform a recommendation to a user. It is essential to use the most recent data, but at the same time even the smallest degree of inaccuracy in a recommendation might end up driving a user away. Here we observed the rise of low-latency stream processing and started unveiling its challenges. We referred to it as stream processing because the data coming in is fundamentally a continuous flow of events, messages, or samples.
Many of the companies interested in data analytics already had large Hadoop clusters deployed, and they were not necessarily ready to move away from the MapReduce model. To get around the latency limitation, some applications started using the approach of micro-batches: instead of waiting to collect huge chunks of data, run a job on smaller chunks that are accumulated over shorter periods of time. The idea of using micro-batches is not necessarily a bad one, and in fact, it did enable applications to obtain insights within shorter time periods.
Micro-batching was a good call at the time, but it was limited. Calibrating the size of the micro-batches is not necessarily trivial, and the latency from ingestion to output was typically of the order of minutes. Getting lower than that was difficult because starting a job alone would take several seconds (I vaguely remember a 30’s ballpark for Hadoop jobs). As a reaction to this inability to process data with lower latency, there were initial attempts to develop a system to process data streams. A couple of early systems coming out of companies in the Web space for stream processing were S4 [1] and Apache Storm [2]. S4 actually came out earlier than Storm, but Storm became way more popular, and it is still widely used. Other systems have followed: Apache Spark [3] supports streaming via micro-batching; Apache Flink [4] fundamentally unifies batch and stream processing, and does not require micro-batching; Heron [5] is a stream processing engine designed to be compatible with Storm. More recently, Apache Samza [6] and Kafka Streams have been developed to leverage Apache Kafka [7] to enable efficient stream processing.
One aspect that all these systems have had in common is that they need some way of capturing data. Ingesting data directly from the source is a bad idea for at least a couple of reasons:
- Data might be shared by multiple applications processing the incoming data, and each application might have its own processing pace and frequency.
- Coupling source and application is typically wrong because the source often has another primary role that is not to serve backend applications. For example, the central purpose of a Web server in applications is to interact with an end user and not to buffer data reliably for say a recommendation application running in the backend.
For these reasons, ingestion of data has typically happened either via a distributed file system (e.g., HDFS) when it is for batch processing or via some messaging substrate that temporarily buffers the incoming events, messages, or samples for stream processing. An application interested in the data can consume it at any time it wants, and with any frequency, it desires, constrained only by the retention policy set up for the incoming data.
Pravega shares this view that it is critical for a successful stream processing application to be able to ingest and serve data efficiently. Pravega departs from traditional messaging systems for ingesting data in a few ways, though. Pravega aims to be a storage solution for streams. An application ingests data into Pravega, and such a stream can be both unbounded in its length and stored for arbitrarily long. Streams in Pravega are elastic: the ingestion capacity of a stream can grow and shrink automatically over time. Its API targets stream applications and, as such, it borrows a number of concepts from successful systems in the space, like Apache Kafka [7]. For example, Pravega enables applications to write events in an append-only fashion, and read these events in the order they have been appended.
In the next section, we describe some core concepts of Pravega, focusing on the features that are part of our first alpha release: Pravega 0.1.0.
Streams and Segments
The core abstraction that Pravega exposes to applications is the stream. Clients can write data to a stream and read data from the same stream. Think of events generated by users of an online application or sensor events in some IoT application for the data to write to read from a Pravega stream. We differentiate between these two types of clients and call them writers and readers, respectively.
A writer appends data to a Pravega stream. The writer has the option of providing a routing key when appending to a stream. Pravega uses the key to map the append to one of the segments forming the stream. The segment is the basic unit that forms streams, and when a writer appends data to a stream, it is actually appending to a segment. Having a stream comprising a number of segments that are open for appends is desirable for parallelism. More segments open implies higher write capacity because writers can append to segments in parallel.
A stream can have an arbitrary number of segments open such that appends can be performed to any of these segments according to the routing key. One important feature of Pravega is that the number of segments of a stream is not necessarily fixed, and the number of open segments can vary according to load. We call this feature stream scaling. When a given segment becomes hot, we split up the key range into multiple new segments. When multiple neighbor segments get cold, we invert the process and merge the key ranges.
The following figure illustrates the changes to a stream due to scaling:
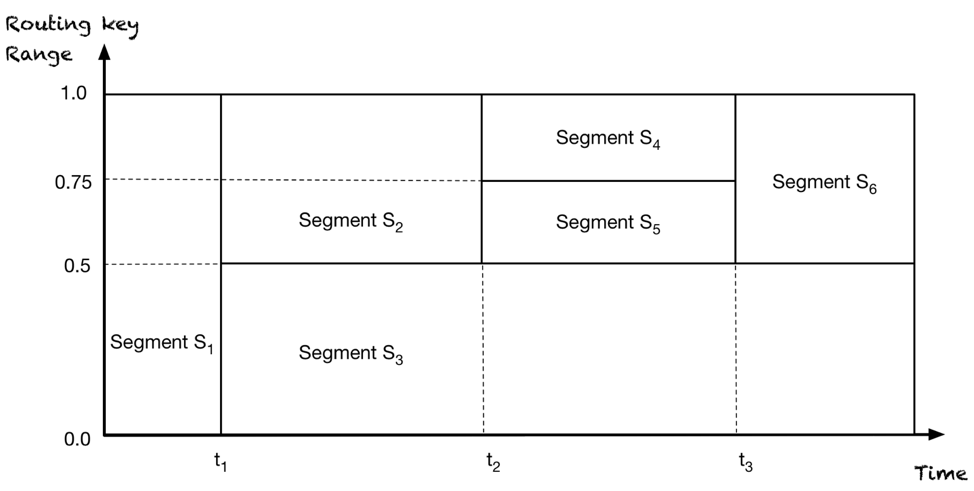
The axes are time (x-axis) and routing key range (y-axis). The stream starts with a single segment (S1). At time t1, the stream scales up and segment S1 splits into segments S2 and S3. At time t2, it scales up again, and segment S2 splits into S4 and S5. Note that nothing happened to S3. At time t3, segments S4 and S5 merge into segment S6.
To enable stream scaling, Pravega has the concept of sealing a segment. Sealing is vital to guarantee that no further appends happen to a segment once there are appends to the new segments. Preventing further writes to segments that have been split or merged is very important to guarantee the order of appends with the same key. For example, say we have a stream initially with a single segment S1 with range [0, 1). At some time T, we split the segment into two new segments S2, S3 with ranges: [0, 0.5), [0.5, 1). If an application that appends data to S2 with some key k at some later time is able to append data to S1 with the same key k, then we have a violation of order because logically all data from S1 have been appended before the data in S2.
Sealing is also crucial for transactions. Pravega enables writers to append transactionally to a stream. To write transactionally, a writer begins a transaction and appends to the stream regularly. Once it is done writing, it commits the transaction. Internally, appends to a transaction happen in separate transactions segments. Such segments are just regular segments, but they are not exposed as part of any stream until they are committed. When a transaction commits, the transaction segments are sealed, and they are merged back to the primary stream segments. At that point, the transaction data becomes visible for readers. If the transaction aborts, then the transaction segments are merely discarded, and they are not visible at all. It is important to highlight that while a transaction is undecided, its data kept separate from the data of the primary segments.
With this approach to implementing transactions, there is no interference of ongoing transactions in the stream segments. Say for the sake of argument that we write directly into the stream segments rather than creating transaction segments. In this case, we would be creating a problem for the readers in at least a couple of ways:
- The reader cannot serve segment data from an open transaction while the transaction remains open, and transactions can take arbitrarily long to either commit or abort.
- In the case that the transaction aborts, stream segments still contain data from the aborted transaction. Segments are appended only and cannot really eliminate data from the middle of a segment.
This observation on transactions strengthens our position of having a flexible scheme based on segments that enables the implementation of such features.
What’s next?
Pravega is very rich in features. This post just scratched the surface of what Pravega does and offers. In future posts, we will be covering specific topics in some depth: the reader and writer APIs, the Pravega architecture, the segment store, the controller, replicating state with revisioned streams and deploying Pravega.
We are currently working on the upcoming 0.2 release. Most of the features for 0.2 are already merged, and we are mostly working on stabilization. If you are interested in contributing and helping out, we would certainly welcome you to our community. Check, for example, our slack channel.
Acknowledgements
Thanks to Srikanth Satya, Jonas Rosland, and Matt Hausmann for the many astute comments that helped to shape and improve this post.
References
[1] L. Neumeyer and B. Robbins and A. Nair and A. Kesari. S4: Distributed Stream Computing Platform. IEEE International Conference on Data Mining Workshops, pp. 170-177, Dec. 2010.
[2] Apache Storm – Distributed and fault-tolerant real-time computation. http://storm.apache.org/.
[3] Zaharia, Matei and Das, Tathagata and Li, Haoyuan and Hunter, Timothy and Shenker, Scott and Stoica, Ion. Discretized Streams: Fault-tolerant Streaming Computation at Scale. Proceedings of the 24th ACM Symposium on Operating Systems Principles, pp. 423–438, 2013.
[4] Carbone, Paris and Ewen, Stephan and Fóra, Gyula and Haridi, Seif and Richter, Stefan and Tzoumas, Kostas. State Management in Apache Flink\&Reg; Consistent Stateful Distributed Stream Processing. Proceedings of the VLDB Endowment, vol. 10, issue 12, pp. 1718–1729, August 2017.
[5] Kulkarni, Sanjeev and Bhagat, Nikunj and Fu, Maosong and Kedigehalli, Vikas and Kellogg, Christopher and Mittal, Sailesh and Patel, Jignesh M. and Ramasamy, Karthik and Taneja, Siddarth. Twitter Heron: Stream Processing at Scale. Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data (SIGMOD ’15), pp. 239–250, 2015.
[6] Noghabi, Shadi A. and Paramasivam, Kartik and Pan, Yi and Ramesh, Navina and Bringhurst, Jon and Gupta, Indranil and Campbell, Roy H. Samza: Stateful Scalable Stream Processing at LinkedIn. Proceedings of the VLDB Endowment, vol. 10, issue 12, pp. 1634–1645, August 2017.
[7] Wang, Guozhang and Koshy, Joel and Subramanian, Sriram and Paramasivam, Kartik and Zadeh, Mammad and Narkhede, Neha and Rao, Jun and Kreps, Jay and Stein, Joe. Building a Replicated Logging System with Apache Kafka. Proceedings of VLDB Endowment, pp. 1654–1655, August 2015.
About the Author:

Flavio Junqueira leads the Pravega team at Dell EMC. He holds a PhD in computer science from the University of California, San Diego and is interested in various aspects of distributed systems, including distributed algorithms, concurrency, and scalability. Previously, Flavio held a software engineer position with Confluent and research positions with Yahoo! Research and Microsoft Research. Flavio has contributed to a few important open-source projects. Most of his current contributions are to the Pravega open-source project, and previously he contributed and started Apache projects such as Apache ZooKeeper and Apache BookKeeper. Flavio coauthored the O’Reilly ZooKeeper: Distributed process coordination book.