Pravega allows the state to be shared in a consistent fashion across multiple cooperating processes distributed in a cluster using a State Synchronizer. This blog details how to use State Synchronizer [1] to build and maintain consistency in a distributed application.
State Synchronizer
In distributed systems, frequently state needs to be shared across multiple instances of an application. If this information is on the data path, it typically goes through whatever datastore is appropriate for the application. Usually, we choose our datastore carefully based on the requirements of our application.
When we have the state that needs to be used by multiple processes, like a schema registry or cluster membership that is not related to the application’s data, it’s worth considering alternative storage options because the requirements might be totally different. Often metadata doesn’t fit neatly in the data path’s schema or consistency model. So, having different storage solutions often makes sense. Sometimes the importance of this is underappreciated and implemented as an afterthought.
In Pravega we encountered a similar kind of problem when Reader Group was used to read events. The previous post discussed scaling, and not how the Readers coordinated membership and which host owns what data. This is a tricky problem, so we need to offer exactly once semantics.
We developed a new model: All instances of a running application have the same object in memory. The data it contains is completely user-defined. It is a normal Java object except that instead of being modified by normal methods, it works like a state machine: there is a separate class for each possible way of modifying it. These classes are serializable and deterministic when run. The object is wrapped by a State Synchronizer, and it will ensure that all hosts have the same updates applied to their objects in the same order. This way the object remains identical everywhere.
This opens the door to a bunch of different use cases that are not handled well by existing solutions.
Existing solutions
The usual solution for Membership and Leader election is to use Apache ZooKeeper[2]. ZooKeeper works well for a shared state that needs to be kept consistent. And ZooKeeper is running somewhere in virtually every datacenter.
A user of ZooKeeper can choose to deploy multiple ensembles and spread applications across them. Doing it enables us to increase the overall capacity, but not in a fine-grained manner. To be resource efficient, it is necessary to execute multiple tasks on the same ensemble, perhaps even spanning multiple applications. Once they reach the capacity of an ensemble, it is not possible to increase it or migrate tasks elsewhere.
There are many storage systems which offer strong consistency in their API and internally rely on ZooKeeper for consistency of their internal metadata. This is a common pattern where one point of consistency can be leveraged to create another. Pravega follows this pattern. It provides strong consistency on a Segment [3] which is guaranteed via its use of write-fencing provided by Apache BookKeeper [4] which is, in turn, uses ZooKeeper for its metadata.
State Synchronizer takes this one step further and provides an abstraction where a Java object can be kept consistent across multiple machines so that all members of a group see the same object even as it is modified.
With the state synchronizer, we store the updates in a log that can be arbitrarily long and make sure that the log is consistently stored and replicated. The application logic is the one responsible for making sense of the updates and applying them, which frees the service from the execution part, making the overall approach highly scalable. So, while Zookeeper is a specific implementation of a replicated state machine; State Synchronizer provides the foundation for implementing an arbitrary replicated state machine.
Pravega uses the State Synchronizer to synchronize data with strong consistency guarantees. Specifically, we use it to coordinate the actions of the readers in a reader group, e.g., the assignment of stream segments across the readers.
Background
Pravega works by storing data in a Tier 1 storage, buffering the data for a while, and then moving the data to Tier 2 for long-term archival. (See, Blog on Pravega Internals). However unlike most of the systems, it competes with (or even those it can write to), it provides strong consistency. In most of the systems, consistency is ultimately anchored by ZooKeeper [14], even though it is never used in the data path (or even most of the metadata paths).
This is possible because once there is a strong consistency, it is possible to leverage it to create a larger system that also provides consistency. In the case of State Synchronizer, it uses the fact that only a single Pravega server can update a Segment at any given time. So it can use atomic compare-and-set operation on the Segment to build up a higher level abstraction while maintaining consistency for the larger application.
The State Synchronizer API [5] can be used across various processes to perform updates on that object. The State Synchronizer ensures that every process that is performing an update on the latest version of that object. Thus, the object is coordinated across a fleet, and everyone sees the same sequence of updates on the same object.
As an example use case, in Pravega we need to coordinate the locations of the Readers in a Reader Group [6].
A set of Readers can be grouped together in order that the set of Events in a Stream can be read in parallel. This grouping of Readers is called a Reader Group. Pravega guarantees that each Event in the Stream is read by exactly one Reader in the Reader Group.
There is a map from Reader to a list of Segments and the offsets in those Segments. We can perform various types of updates: updating the position for a Segment, replacing a Segment with its successors when Segments split or merge [7], or simply rebalancing by reassigning a Segment to a different Reader. Each of these updates only makes sense in certain situations. (A Reader cannot update the position for a Segment it does not own. Rebalancing only makes sense if the Reader receiving the Segment is online.) So, while the update rate and data aren’t very large, the data needs to be consistent. There isn’t any clear ‘owner’ as many hosts can update the data. That makes this a perfect case for using State Synchronizer (Which is what we do).
How does State Synchronizer work?
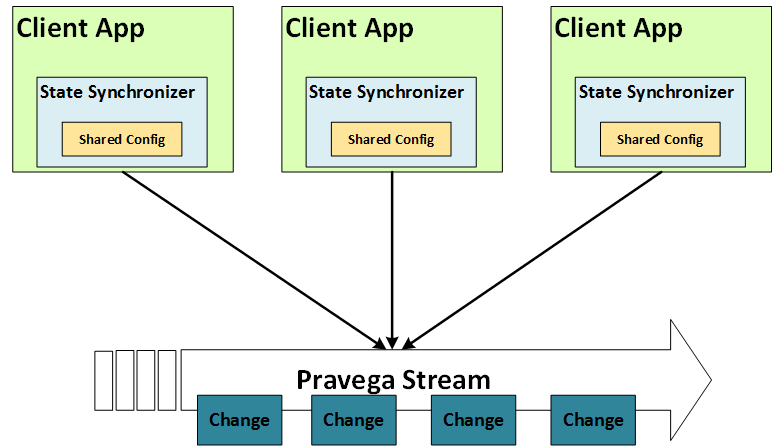
The idea is to use a Stream to persist a sequence of changes for a shared state. And allow various applications to use the Pravega Java Client Library (as shown in the diagram below) to concurrently read and write the shared state in a consistent fashion.
High-level View of State Synchronizer
To use it we create a normal Java Object that encapsulates the data we want to track. For each possible update to that object, we write a class with an applyTo method that takes in an instance of that state object and returns a state object with the update. (The update operation could be either modification or generation of the new object.) Then we provide a class that can serialize and deserialize these update objects. Then using the State Synchronizer interface [8], we can update our state object from any host in our fleet and guarantee that all hosts that they will see the same updates in the same order. (Behind the scenes all updates are written to Pravega, and Pravega guarantees their order). Assuming that the applyTo method is deterministic as all hosts will arrive at the same State object.
Because the state is totally user-defined, an application could perform any of the following:
Track host membership
Do leader election
Store configs
Used to coordinate a more complicated process.
Or as noted above, keep track of progress and assignment of work.
But how does it guarantee consistency? After all two hosts could try to write updates at the same time.
This is done using optimistic concurrency by making append of updates conditional. Internally the State Synchronizer is tracking the amount of data read. When new updates arrive, it increments a counter by the length of the data. Then when an update is requested, it serializes the update and sends it to Pravega as a conditional append.
To the server the request looks like the following:
“Append this data if and only if is the sum total of the lengths all data that has been written to this stream.”
On the server side, the server will compare the length of the data to the value provided by the client. If the client value matches, then the data is appended. Otherwise, an error is returned to the caller. When the State Synchronizer gets this error, it can read the new updates that it was not aware of and re-run its logic to see if the update should be attempted again.
By tracking the length on the client as well as the server updates can be performed as quickly as data can be written and read from Pravega if there is no contention, i.e., only one client at a time is updating. Because the State Synchronizer uses optimistic concurrency for its updates, it is only appropriate to use when that optimism is justified. If many hosts contend to update concurrently, performance decreases. However, irrespective of lowered throughput, it will continue to provide consistent results, and always make forward progress. In general, though it is better to avoid contention and keep the state small.
Using State Synchronizer
As an example of how State Synchronizer can be used, when we want all the readers in a ReaderGroup to agree on who is reading what data. We define a data structure that holds the information we want to track. Then we can define any methods we want to read from it. (Just like any other object). For each way, the data can be updated (AddNewReader, RemoveReader, ReassignSegment, etc.), we create a corresponding class that implements the Update interface. The interface has a single method applyTo which provides the state object to be updated. It is guaranteed that the object passed to the applyTo method will have all the previously written updates already applied.
To detect if a host was alive, we could create a membership tracker object. It could keep a timestamp for the last time each host was heard from. Then a host could be declared dead if it did not heartbeat in a sufficiently long time. In this case, we would define update objects like AddNewHost, Heartbeat, DeclareDead, etc.
We’ve created some pre-made examples which should be helpful to look at:
The leader election example will allow many hosts to join a group, and one will be notified as a leader. Callbacks are used to notify it when it loses leadership.
Keeping state small
State Synchronizer works best when the state and the serialized updates are small. The state object needs to be kept in memory and updates need to be re-read to reconstruct the object. To prevent applications from accidentally blowing things up, Pravega imposes a 1MB limit for the state object.
The state should also be unambiguous. It’s a good idea to include configuration parameters that indicate how the data in the state object should be interpreted in the state object itself. In the membership tracker example, the timeout we use to track whether a member is still part of the set should be part of the state. This acts as a safeguard to ensure that all the hosts agree on the meaning of the data.
The natural way to scale up is to use multiple different objects. Unlike a system like Zookeeper where everything ends up in the same ensemble, you can have as many State Synchronizers as you like , and each will be independent. So, if multiple pieces of data are unrelated or not atomically consistent with one another, it is best to put them behind different State Synchronizers. Also, remember it is possible to use URLs or IDs to refer to external data.
Another best practice is to keep our updates simple. The UpdateGenerator function can return multiple updates. If it does, then they will be appended atomically. (Meaning they will either all go in or none of them will, and no other updates will come in between them). Consequently, for simplicity, it may be helpful to break up a complex operation into multiple updates. This allows our update objects to be kept small and simple.
Things to Remember
UpdateGenerators
On the client side, the following is the signature to update:
This is sometimes quite helpful. For example when we are managing the state of a Reader Group, if we perform an update to rebalance the Readers, our initial attempt might fail, but then looking at the new state, we might decide that rebalancing isn’t needed after all. Below is a simplified example where the state being managed is a Set of values:Instead of passing an update directly, the application passes an UpdateGenerator, which is a function that takes the current state and returns the updates that should be applied. This does not modify the state object. Instead, the proposed updates are conditionally appended to the backing Segment. So applying an update may fail due to simultaneous writes made by another host to the state. In such situations, the update generator is simply invoked again with the new state object (theUpdateGeneratormay be invoked multiple times).
This is sometimes quite helpful. For example when we are managing the state of a ReaderGroup, if we perform an update to rebalance the Readers, our initial attempt might fail, but then looking at the new state, we might decide that rebalancing isn’t needed after all. Below is a simplified example where the state being managed is a Set of values:
public void add(T value) {
stateSynchronizer.updateState((set, updates) -> {
if (!set.impl.contains(value)) {
updates.add(new AddToSet<>(value));
}
});
}
Here the function uses the passed in state object to check to see if the item to be added is already present.
It is important to note that functions to update things outside of the state object should NOT be invoked during our update method. To help with this situation, we have added another API:
This signature is similar to the UpdateState call, but with the added advantage that the UpdateGenerator can return a result. The result of the final invocation of the UpdateGenerator is returned to the caller. This is useful if action needs to be taken in response to the update performed.
For example, when we add new Readers to a Reader Group we do the following:
To get the latest information, we need to call fetchUpdates() [11]. This method is also called internally by updateState() [12]. The state object will only change when one of these two methods is invoked. This makes it easy to reason about changes to the state object.
It is an anti-pattern to call fetchUpdates() followed by an unconditional update. Because the state object can be updated by another host concurrently leading to a race condition, instead updates that depend on the state should always be made using updateState().
Unconditional updates
An unconditional update will always put the update object onto the Pravega Stream regardless of what previous updates are already there. The advantage of an unconditional update is that it avoids contention. However, this does not mean we are giving up consistency altogether. The update still runs the applyTo method with all of the previous updates applied to it. (Just like a conditional update would). So, it is perfectly possible to have an update unconditionally written, but then looking at the state inside of the applyTo method decides that nothing needs to be done. In which case the update will be in the Stream and all hosts will apply the update, but doing so will have no effect.
For example, in the case of a set, the add method mentioned above could be implemented more simply as:
public void add(T value) {
stateSynchronizer.updateStateUnconditionally(
new AddToSet<>(value));
}
Assuming that AddToSet.applyTo is idempotent. (Which in the case of a set it should be).
Thread Safety
All the methods on the State Synchronizer interface are thread safe. No locking is required when invoking a method on the synchronizer or before reading the state, as thread safety will be managed internally
However, if one thread calls update and in parallel, another thread is reading the state object, and the update modifies the object in place (as opposed to returning a new state object). Then there could be a race with respect to the read. This can be avoided by any of the following:
Using a single thread to manage the state object.
Have the update function return a new object as opposed to modifying the existing one.
Use synchronization in the methods of the state object.
(In this case, it is worth knowing that the update function synchronizes on the state object itself when calling applyTo)
Compacting data
Compacting data
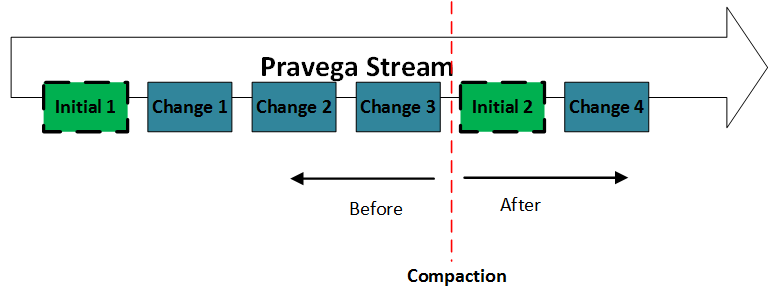
As the updates are being written to Pravega continuously, the amount of data stored grows over time. To prevent the indefinite growth of data storage, data can be occasionally compacted [13] by compressing and removing old state updates so that only the most recent version of the state is kept in the backing stream. This is done using the method:
This allows the existing state object to be re-written in a more compact form. The compacted state is written similarly to a normal update, the compacted state that is returned from the function provided is written to the stream. Once it is written all the updates before it is dropped. Thereby replacing the history of updates, with a single update containing the current value.
When to compact?
Compaction is no more expensive than an update of equivalent size. So compaction can be performed anytime the list of updates becomes undesirably large. Generally, this is performed by maintaining a counter and compacting the state after N updates. Any replica can perform the compaction, but they should not attempt too frequently as it may waste space. A simple way to do this is to include a counter of the number of updates since the last compaction in the state. Compaction and updates cannot be performed in the same operation. They must be done in two separate calls.
Performing Compaction
Wrapping up
Take a look at State Synchronizer in GitHub it’s an interesting and unique tool. Pravega uses State Synchronizer internally, to manage the state of Reader Groups and Readers distributed throughout the network.
Tom Kaitchuck is among the original group of developers of the Pravega project and is currently a core contributor employed by Dell. He holds a BS Degree from Valparaiso University. Tom an ardent open source software developer previously held senior software developer positions with Google and Amazon. Tom’s interests include Distributed systems, Asynchronous communication, Concurrency, Scaling systems, Consistency models.


 Tom Kaitchuck is among the original group of developers of the Pravega project and is currently a core contributor employed by Dell. He holds a BS Degree from Valparaiso University. Tom an ardent open source software developer previously held senior software developer positions with Google and Amazon. Tom’s interests include Distributed systems, Asynchronous communication, Concurrency, Scaling systems, Consistency models.
Tom Kaitchuck is among the original group of developers of the Pravega project and is currently a core contributor employed by Dell. He holds a BS Degree from Valparaiso University. Tom an ardent open source software developer previously held senior software developer positions with Google and Amazon. Tom’s interests include Distributed systems, Asynchronous communication, Concurrency, Scaling systems, Consistency models.