
Pravega Watermarking Support
Tom Kaitchuck and Flavio Junqueira
Motivation
Stream processing broadly refers to the ability to ingest data from unbounded sources and processing such data as it is ingested. The data can be user-generated, like in social networks or other online application, or machine-generated, like in server telemetry or sensor samples from IoT and Edge applications [1].
Stream processing applications typically process data following the order in which the data is produced. Following a total order strictly is often not practically possible for a couple of important reasons:
- The source is not a single element as it might comprise multiple users, servers, or gateways;
- Inherent choices of the application design might cause items to be ingested and processed out of order.
Consequently, the order in Pravega and similar systems refers to the order in which the data is ingested and determined by some concept like keys connecting elements of the data stream.
The ability to process data following the order of generation, even if only loosely, is one of the most interesting aspects of stream processing as it enables an application to establish temporal correlations about the different events. For example, an application is capable of asking questions such as how many distinct users signed in during the last hour or how many distinct sensors have reported an anomaly in the past 10 minutes. To implement and answer such queries, the application must be able to produce results for every reporting period, every hour in the first example and every 10 minutes in the second. These reporting periods are often referred to as time windows [2].
Processing the data as it is being produced enables the application to output results as they are generated. For a bounded data set (one that does not add further data), it is possible to perform time window aggregations for all windows in parallel using map-reduce. The same is not feasable for an unbounded data set (a stream) because the data is dynamically and continuously generated. As such, for a continuously generated source, the choices are to periodically process snapshots or deltas of the data set in a map-reduce manner, which induces a longer time to process, or to process data in a stream fashion as it is ingested. The latter enables much lower latency end-to-end when compared to processing periodically.
To perform computations like window aggregations, it is necessary to have some time reference and to have data elements of the stream (e.g., messages, events, records) associated with a time value. Without a time reference, an application is not able to determine to what window a particular element belongs to.
The time domains typically used to talk about a time reference are event time and processing time [2]. Event time corresponds to the time that the source assigns to the events; it is expected to be the wallclock time during which the event was generated. Processing time uses the clock of the element processing the data as a reference. The time associated with an event is determined either at the time the application reads the data from Pravega or at the time that the event is processed. We additionally consider ingestion time, which corresponds to the time during which the data has been received by the application ingesting it. For example, in applications that use Pravega to store stream data, the ingestion time corresponds to the time during which the event is written to a Pravega stream. Figure 1 illustrates the three time domains.
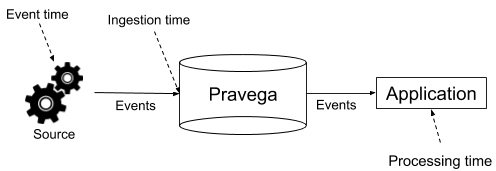
As each one of these time domains associates a time value to an event at different points of the lifecycle of the event, it is expected that there are discrepancies. The difference between the time values induced by event time compared to ingestion time can be typically short when the source sends the event immediately upon generation, but due to connectivity, it might cause some outliers and consequently more significant differences. The difference between ingestion time and processing time depends on the time difference between ingestion and processing. In fact, for Pravega, that difference can be really long as Pravega is a storage system and stream data can exist in Pravega and be processed by applications arbitrarily later compared to when it was ingested. In Pravega, we use historical data to refer to such data and denote stream data that is not fresh, that has been ingested for arbitrarily long.
Being able to associate time values to events individually using one of the time domains we discussed is not sufficient. The application can infer from timestamps which reporting period individual events belong to, but how does it know that it has received all events for a window and that it can close a given window? Closing windows is simple with processing time under the assumption that the processing time clock is continuously advancing, but it is not the same for event or ingestion time. For event and ingestion time, the application processing the data needs to know, even if only approximately, that it can close a given window and report the result of the computation. Of course, it is also possible to never close a window and keep continuously re-processing the window data, but at some point, the application needs to make a call to use a final result and move on, which is equivalent to closing the window.
To enable the application to make such assertions about the end of windows, it needs a lower bound for the time of events and those bounds are called watermarks. A watermark w asserts that all events with an assigned timestamp lower than w have been read or processed, depending on the context. There is always a chance of late events, though, and the specific way to handle and minimize late events depends on the application. Figure 2 illustrates the concept.

To compute window aggregates, we need to be able to map events to windows and to know when to close the windows (calculate the aggregate for the window). It is not sufficient to assign sequentially, even if we assume a single sequence of events, because events can be out of order. We illustrate it with events 7 and 8 in the figure. Consequently, we need to have a time reference per event so that we know which window to assign it to. We also need to know when to close the window, and the watermark is the abstraction that enables window to be closed by providing a time bound. In practice, it is very difficult to provide strict guarantees for watermarks. The asynchronous nature of distributed systems makes it complicated to offer strong guarantees about late events. Also, in the interest of progress, it is often a desirable choice to close windows earlier and risk some small fraction of late events. Such a choice is typically one that is application-dependent.
In this post, we discuss the support we have added in Pravega for event and ingestion time. One of the key challenges we had to overcome is the provisioning of watermarks in the presence of changes to the set of segments of a stream via auto-scaling. We have added support internally to the Pravega reader group to simplify the connection with stream processors, such as Apache Flink. We use Apache Flink as a motivating example of a stream processor that relies on watermarks and discuss both the support that Flink offers for watermarking as well as the integration with the Flink connector for Pravega. We conclude with observations on how to integrate with an arbitrary application and some remarks on our experience with the feature so far.
A running example: Apache Flink
Apache Flink is an open-source platform for stream and batch processing [3], and we have written a connector to enable applications to process Pravega stream data with Flink [4]. Flink comprises a programming model for applications to write jobs and a distributed runtime environment for executing Flink programs. At run time, the Flink environment maps a program into a dataflow comprising one or more sources, transformation operators, and one or more sinks. The source is the most interesting element in this discussion about watermarking because it is one that leverages the time information out of Pravega to produce watermarks.
Watermarking is a core concept in Apache Flink [5]. It enables time-based computations like time windows under different time domains: event, ingestion, and processing time. In Flink, they are called time characteristics. Event and ingestion time are defined differently in Flink. For Flink, ingestion time denotes the time that events get into the Flink dataflow, rather than the time that events are ingested into the data pipeline say when written to Pravega. Event time denotes the time assigned by the application, which captures any form of time assignment and watermarking determined by the application, including assignments at the source based on time information that Pravega propagates. Event time is consequently the Flink time characteristic that captures event and ingestion time according to Pravega. Figure 3 illustrates the different time characteristics and contrast to how we see them in Pravega.
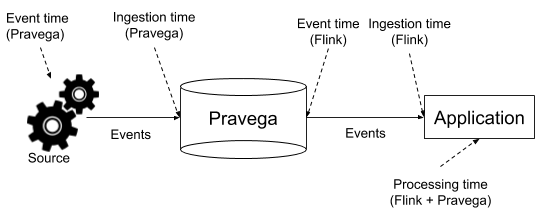
To determine what time characteristic to use for a job, Flink expects the program to set it in the execution environment [5]:
When working with event time in Flink, it is necessary to assign timestamps to events, and the system expects watermarks to indicate the progression of event time. There are two provided ways to do it: via the source directly or via a timestamp assigner (which also emits watermarks). The timestamp assigner is an element introduced as part of the job specification, and it needs to be introduced before the first operation using time, typically immediately after the source. The assigner overwrites timestamps and watermarks generated by the source [6].
The option that is most relevant in the case of Pravega is having the source assigning timestamps and emitting watermarks. With this option, we can add support to the Pravega connector for Flink to assign timestamps and emit watermarks using the mechanism in Pravega that we describe in this post. Flink sources that support event time need to call
- SourceContext<T>#collectWithTimestamp(T element, long timestamp): to emit an event from the source, assigning a timestamp to it
- SourceContext<T>#emitWatermark(Watermark mark): to emit a watermark
In the next two sections, we motivate our design for supporting watermarks in Pravega and present it. Once we have discussed the design and the implementation, we come back to present more detail on the connector integration.
Why is it challenging?
Let’s assume that we have a simple application with a set of sensors emitting events, a Pravega stream, and a Flink job. It does not matter what the job does precisely at this point, but let’s say that it is performing some form of window aggregation over the Pravega stream and it needs to know the boundaries of time windows.
If the sensors are able to assign timestamps, in which case the events are written to the Pravega stream carrying a timestamp, then the Flink job source can extract those timestamps and have some notion of time progression. Even though this is a valid approach, there are two critical shortcomings with doing it this way:
- For any given timestamp, we do not know whether there is another event coming with that timestamp or not, so we cannot advance the watermark;
- In the case the Flink source does not receive any events, it does not know whether event time is advancing and there is simply no new data or the system is being asynchronous (i.e., events are arbitrarily delayed).
In general, it is not possible to avoid late events altogether as there are many circumstances that could induce such late events, such as connectivity and node unavailability. But, the source and the application typically have information about event time (e.g., its own clock) and we ideally propagate such information to enable the Flink source to advance event time more accurately.
Let’s now look at how we can do it with Pravega. Say that we periodically add marks to the sequence of bytes of a Pravega stream to indicate the progression of event time. Such marks indicate that all events with event time earlier than one of the marks have been written. There are three critical observations about doing it:
- A Pravega stream with multiple writers needs to coordinate the addition of marks to make sure they reflect the state of all writers
- A Pravega stream is rarely only a single sequence of bytes, and it is typically formed of multiple parallel segments
- Internally, segments are sequences of bytes, so mixing control data like marks with application data is not desirable
To address (1), we need some mechanism that considers all present writers, while (2) requires that a mark reflects a position across segments. For (3), we need to maintain the marks externally. Figure 4 illustrates the time flow for an application ingesting events to Pravega and processing them.
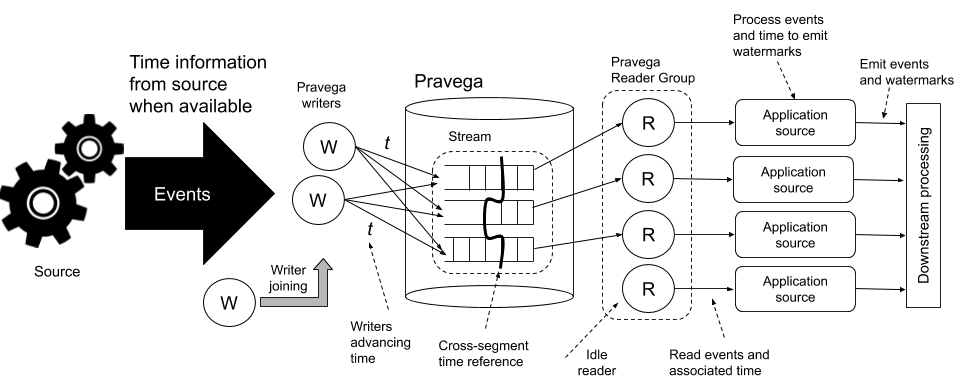
Considering all writers is not trivial because writers may come and go. Any mechanism we choose needs to consider the dynamics of the set of writers. To keep marks externally while mapping them to corresponding positions across segments, we need a data structure that maintains such a mapping of segments to offsets, and we need to maintain such marks separate from the stream data, say in a separate segment.
It remains to address the point of idle readers. Reader groups coordinate to assign stream segments to readers in the group [7]. Say that a given reader has no segment assigned. This scenario is possible, for example, when there are more readers in the group than segments to assign. In this case, how does a reader with no segments assigned know that event time is advancing? To ensure that idle readers are able to emit watermarks despite the absence of assigned segments, we coordinate the advancement of event time via the state synchronizer of the reader group. This coordination enables all readers to advance event time independent of segment assignments.
Up to this point, we have been talking about time without saying where the time reference is coming from. It is on purpose; we do not want to constrain what the applications have as a time reference or even when this time reference has existed. The time reference can be wallclock time and very close to the current time when the data is generated live, or it can be generated at some arbitrary point in the past when reading events from a file. We do not attempt to prescribe or enforce ways to assign time, and specifically for event time, we expect the application to set it in a way that is meaningful according to its design.
In the next sections, we elaborate on our design and implementation. Many of the abstract concepts we have been discussing materialize in the remaining sections.
Pravega support for watermarking
Pravega watermarking consists of three major parts as laid out in the proposal [8]:
Obtaining the time
First is an API on the EventStreamWriter to note the time. This allows a writing application to indicate to Pravega what time the data they are writing corresponds to.
Here the noteTime API may be called periodically to indicate the time below which all events have been written.
The API is structured this way so that applications that aren’t concerned about watermarking don’t have to do anything. Additionally, it enables the application to define its own notion of time.
Similarly, for transactional writers, there is also an optional parameter on the commit() method on Transaction which allows the application to specify the time that corresponds to data that was written in a transaction.
The noteTime and the commit methods take a timestamp, rather than just looking at the system clock. This allows time to be defined in terms of event time.
If the process writing is not the one generating the events, such as if the events are coming from a web front end, a mobile app, or an embedded device, there may be a lag between the time they are written and the time they occurred. This also applies if the events are themselves derivative of some upstream source. It is common, for example, to read data from one stream, process the data in some way (by aggregating it for example), and then write it out to another stream.
If your application does not need to define time and ingest time can be used, there is a configuration parameter automaticallyNoteTime to enable this. This is configured like so:
With this option turned on, no calls to noteTime are required at all.
Once a time has been obtained a unified view is needed for all writers on the stream. To perform this aggregation, internally the client combines the time with the current position of the writer and sends this information to the Controller.
Aggregating timestamps from multiple writers
The controller receives these timestamps and positions from all the writers. It can aggregate this information by taking the timestamps from all the writers on the stream and write out a stream cut that is greater than or equal to the maximum of all writer’s positions and a timestamp that is the minimum of all the writers.
For example:
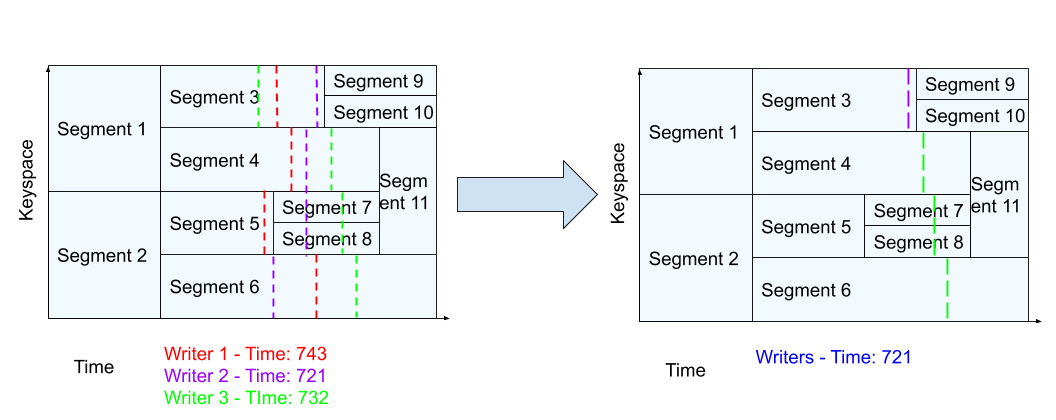
By aggregating the timestamps in this way, a reader that is at a position above a given streamcut will be guaranteed that is has received all the events.
Of course, writers can come and go. Naturally it would be undesirable to hold up advancing time forever if a writer shutdown and never came back. To prevent this there is a configuration parameter timestampAggregationTimeout on the stream. This configures the time after which a writer that has not been heard from will be excluded from the time window calculation.
To make the aggregated information available to the readers, the Controller writes the aggregated time and stream cut to a special segment. (This is internally referred to as the “mark” segment.) The readers can read from this special segment to determine their position in the stream.
Readers get a time window
Finally, the readers coordinate their positions with each other to obtain their combined position in terms of a StreamCut.
This is a bit tricky because to know where the readers are relative to the stream cuts recorded in the “mark” segment, and they need to produce an aggregated stream cut. This requires the coordination of all the readers in the reader group. We do this by having each reader record their position in a StateSynchronizer.
Once a position is obtained, it needs to be compared. This doesn’t actually produce a unique value. For example, consider a reader group at this StreamCut:

In this instance, the reader group is partially ahead of some timestamps but also partly behind them. This makes sense when you consider the original motivation for watermarks. Data is being processed on multiple hosts in parallel, and we want to establish the point below which all the events have been processed.
For this reason, readers receive a TimeWindow rather than a single timestamp. This provides the range over which the readers may be spread. In the above example, the time bounds would be T2 and T5. A time window can be obtained by calling:
TimeWindow window = reader.getTimeWindow();
During this process, the primary invariant that is maintained is that the lower time bound for a reader should indicate all events with older times have definitely been read. There are a couple of edge cases worth noting.
- The reader group could be before the first timestamps recorded for the stream; in which case the lower time stamp can’t be defined. All that can be said is the group is before the first timestamp.
- The reader group could be passed the last ‘mark’ recorded by the controller. For example, if a reader group that is at the tail of the stream and is keeping up with incoming data, it will likely process events before the controller can aggregate the time stamps. In this case, when an application calls getTimeWindow(), the returned TimeWindow may have an upperTimeBound which is null. Similarly, the lowerTimeBound may lag behind the readers’ actual position because it must wait for the time information to arrive.
- The TimeWindow is based on where the readers have read, not what the application processed (as Pravega would have no way of knowing that). So, if the application calls readerOffline() because a reader has died and indicates that events need to be re-processed, then TimeWindows may go backwards to reflect the events that need to be re-read because they were lost when the reader processing them died.
Connecting to processing logic
On the EventStreamReader interface, the getTimeWindow() returns a TimeWindow. The TimeWindow object provides both an upper and lower bound on time.
This is a pull based model, rather than push based one which hypothetically could be made by injecting pseudo-events into the stream. This has a few advantages; it doesn’t mandate handling of time for every stream, it allows time to advance on a stream without any events, but most importantly it provides flexibility in how often the TimeWindow is computed.
The TimeWindow reflects the current position in the stream, so it can be called following every readNextEvent() call if desired, or just periodically to provide support for grouping events into windows.
Flink connector example
An example of this can be seen in the Pravega Flink connector which implements the interface “TimestampsAndPeriodicWatermarksOperator” by doing:
Here the connector is getting the timewindow and if it allows it to advance the Flink watermark, emitting a new watermark and scheduling the task to be re-run after a configured interval.
Because this logic is implemented in the connector itself, all Flink applications using Pravega can gain the benefits of event time or ingest time watermarking using all the standard Flink APIs.
Conclusion
Tailing a stream and processing historical stream data are both integral parts of the Pravega story. Pravega stores stream data enabling applications to process stream data as soon as it is available or arbitrarily later in the future, using the same API. For consistency of results, it is often critical the stream data has a time reference so that results are independent of when the stream data is processed, and that it bounds time to enable computation over time windows. The need for such time information for stream data is what led us to work on watermarking support for Pravega.
Our watermarking support consists of associating timestamps to data written to a Pravega stream, producing stream cuts that represent positions in the stream according to the timestamps, and exposing time information through the readers to enable the application to emit watermarks. The time information that a reader obtains is a range across all readers, according to their positions, giving both a bound on the minimum read so far and the spread across the group.
Our approach is general and supports any application able to produce monotonically increasing timestamps. We have chosen Apache Flink for the initial integration due to its advanced support for window aggregation and watermarking. We added Flink support to the Pravega Flink connector, enabling Flink jobs to benefit from watermarks when using Pravega. We expect future Pravega connectors to provide similar support, and standalone applications to implement it themselves as the logic required to use the API presented in this post is expected to be straightforward.
Acknowledgments
Special thanks to Srikanth Satya, Ashish Batwara, and Igor Medvedev for very useful comments that made this post better.
Authors
 Tom Kaitchuck is among the original group of developers of the Pravega project and is currently a core contributor employed by Dell. He holds a BS Degree from Valparaiso University. Tom an ardent open source software developer previously held senior software developer positions with Google and Amazon. Tom’s interests include Distributed systems, Asynchronous communication, Concurrency, Scaling systems, Consistency models.
Tom Kaitchuck is among the original group of developers of the Pravega project and is currently a core contributor employed by Dell. He holds a BS Degree from Valparaiso University. Tom an ardent open source software developer previously held senior software developer positions with Google and Amazon. Tom’s interests include Distributed systems, Asynchronous communication, Concurrency, Scaling systems, Consistency models.

Flavio Junqueira is a Senior Distinguished Engineer at Dell EMC. He holds a PhD in computer science from the University of California, San Diego and is interested in various aspects of distributed systems, including distributed algorithms, concurrency, and scalability. Previously, Flavio held a software engineer position with Confluent and research positions with Yahoo! Research and Microsoft Research. Flavio has contributed to a few important open-source projects. Most of his current contributions are to the Pravega open-source project, and previously he contributed and started Apache projects such as Apache ZooKeeper and Apache BookKeeper. Flavio coauthored the O’Reilly ZooKeeper: Distributed process coordination book.
References
[1] McKinsey & Company. The Internet of Things: Mapping the value beyond the hype.
[2] T. Akidau et al., “The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing”, Proceedings of the VLDB Endowment, vol. 8 (2015), pp. 1792-1803
[3] Apache Flink. https://flink.apache.org
[4] Pravega connector for Flink. https://github.com/pravega/flink-connectors
[5] Flink Event Time. https://ci.apache.org/projects/flink/flink-docs-stable/dev/event_time.html
[6] Generating Timestamps / Watermarks.
https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/event_timestamps_watermarks.html
[7] Flavio Junqueira. “Streams In and out of Pravega” https://cncf.pravega.io/blog/2018/02/12/streams-in-and-out-of-pravega/
[8] PDP-33 Watermarking. https://github.com/pravega/pravega/wiki/PDP-33:-Watermarking