
Introduction
The fundamentals of stream semantics in Pravega are learned through familiarity with its client APIs. In this article, we will overview Pravega’s client APIs with a handful of simple examples. As we reach the end, you should see Pravega in action, understand the guarantees afforded by Pravega streams, and have some familiarity with several of the facilities provided by the client API.
Pravega client APIs provide read and write access to data streams. Streams store sequences of bytes. Writers commit new sequences of bytes at the tail position(s) of a stream. Writes to a single stream can be split across shards or segments; and, when writes are accompanied by routing keys, these writes can be ordered within their determined segments.
Streams have scaling policies that allow them to split into several parallel segments. In UNIX, a stream is akin to writing a file in append mode, where several writers are guaranteed to append after each other and not overwrite each other’s contents. An open append-only file typically has one data stream, whereas a stream in Pravega can have many parallel data streams, called segments, allowing an influx of writes to scale horizontally across a cluster, as according to scaling policies and routing keys. Unlike most other distributed message passing or data storage systems, the parallelism of a stream can change over time according to write throughput factors. Writes can be distributed across these parallel stream segments, and there can become more of them or fewer of them over time.
A stream with its scaling policy fixed to a single segment is very similar to an append-only file handle in UNIX, where multiple writers’ contents are naturally ordered by when their writes arrived, without a threat of overwrites. As a stream splits into more segments for more parallel writes, order can be preserved among specific writes by using keys. A routing key routes a write deterministically to one and only one segment, allowing a natural order of writes to continue to be preserved.
To use Pravega wisely, one must consider the above factors with respect to their application. What writes need to be ordered? How many different streams do you have? What routing keys are needed? Etc. For example, consider the impact of certain types of stream queries: putting all events from all sensors into a single stream may require reading all events from all sensors when reprocessing events from a single sensor.
In this article, we will first cover the event stream client and its semantics of ordered writes with sequential reads in single-segment streams, unordered writes with non-sequential reads in multi-segment streams, and ordered writes with semi-sequential reads using routing keys in multi-segment streams. We will then cover the batch and byte stream clients and their unique capabilities.
Overviewing single-segment streams that act like files
Connecting to and configuring Pravega
Rather than find a complicated example use-case that puts Pravega through its paces in terms of streams and segments and dynamic scaling, let’s first get to know Pravega’s client APIs by using streams with a fixed scaling policy of 1 segment. We’ll need a StreamConfiguration to define this:
With this streamConfig, we can create streams that feel a bit more like traditional append-only files. Streams exist within scopes, which provide a namespace for related streams. We use a StreamManager to tell a Pravega cluster controller to create our scope and our streams. But first, in order to work with Pravega, we will need to know at least one controller address:
To use this URI, we must stand up a controller at localhost:9090 by cloning Pravega’s GitHub repo and running, ./gradlew :standalone:startStandalone:
With a standalone server running, we can invoke the StreamManager to create our scope and a numbers stream:
It is important to note that all managers, factories and clients ought to be closed and are auto-closeable. Being sure to close your instances will avoid resource leaks or untimely resource deallocation.
Whether we’re creating a reader or writer, we need a ClientConfig to at least tell the client its controller addresses:
Sequential writes and reads on a single-segment stream
Let’s start by creating an EventStreamWriter for storing some numbers:
And use it to write some numbers (note that writeEvent() returns a CompletableFuture, which can be captured for use or will be resolved when calling flush() or close(), and, if destined for the same segment, the futures write in the order writeEvent() is called):
Notice how we’re able to write unadorned native Java objects and primitives to a stream. When instantiating the EventStreamWriter above, we passed in a JavaSerializer<Integer> instance. Pravega uses a Serializer interface in its writers and readers to simplify the act of writing and reading an object’s bytes to and from streams. The JavaSerializer can handle any Serializable object. If you’ll be passing around Strings, be sure to look at UTF8StringSerializer for a more compatible in-stream encoding. For interoperability, you’ll probably want to use a JsonSerializer, CborSerializer or AvroSerializer, but, for illustration purposes, we’re using the built in and less portable JavaSerializer. Pravega Schema Registry is another appealing option.
We can read back these events using a reader. Readers are associated with reader groups, which track the readers’ progress and allow more than one reader to coordinate over which segments they’ll read.
Here we used the ReaderGroupManager to create a new reader group on numbers called numReader.
Now we can attach a single EventStreamReader instance to our reader group and read our 3 numbers from our numbers stream:
Outputs:
1 2 3
Note that readNextEvent() takes a timeout in milliseconds, which is the maximum amount of time that the call will block before returning an EventRead instance that returns null on getEvent(). In this example, we are terminating on the timeout that occurs when we reach the tail of the stream, but timeouts can occur before a reader reaches the tail. Something called checkpoints can also cause getEvent() to return null. A checkpoint is a special event processed by reader groups which allows each reader to ensure its progress is persisted and causes a reader group to save its positions across a stream. An event can be determined to be a checkpoint event with isCheckpoint(). For these reasons, a more robust looping mechanism should be used in practical applications. We will improve this loop the next time we see it below.
Reader group good-to-knows
If a reader is not properly closed, before it can come back online or before its work can be assigned to other readers, it will need to be explicitly marked as offline in the reader group, and, when doing so, it’s last known position can be provided. If a reader is gracefully shutdown, then it is removed from its reader group and its segments are redistributed among the remaining readers. A reader group cannot presume when a reader has shutdown ungracefully. A dead reader needs to be marked as offline for other readers to pick up its work or for that reader to rejoin the reader group, otherwise the reader’s assigned segments will never be read:
A reader group tracks each reader’s position in a stream. If all readers in a reader group are closed, when they come back online, they will automatically pick up where they left off. Should any readers remain online, they will pick up the work of the offline readers. When a closed or offline reader comes back online, it joins an active reader group as a new reader and negotiates a share of the work.
Pravega Samples has a ReaderGroupPruner example that shows how to detect any dead workers and call readerOffline(readerId, lastPosition) on their behalf. The null value for lastPosition above indicates that it should use the position(s) for that reader stored in the last reader group checkpoint or the beginning of the stream if there are no checkpoints. This could lead to duplicates if events are not idempotent or if checkpoints aren’t explicitly used to ensure exactly once processing.
In order to re-use reader group names and reader IDs when starting over from the beginning of a stream or from a newly chosen stream cut, you need to either delete and recreate the reader group or reset the reader group’s ReaderGroupConfig:
Pravega keeps reader group metadata for you inside internal metadata streams until you decide to delete it. When you are finished with a reader group, it is advised to delete the reader group as shown above.
Seeking around and to the tail end of a stream
We’ve just explored reading from the beginning of a stream to the end in sequential order. But can we seek through the stream? Of course, we can! Let’s explore that now using a new tailNumReader reader group that is given the current tail stream cut as its starting point (a stream cut is a set of positions across all stream segments within a specific time step or epoch, a tail is the end of a stream at that point in time):
We can now create an EventStreamReader instance named tailReader that can read from the end of the stream. If we append to the stream, we will only read new events with this reader group. Let’s append to numbers and read with tailNumReader. As already mentioned, our while loop was a bit too simplistic previously. Let’s see about improving things further by checking for the end of stream by tracking unread bytes available:
Outputs:
4 5 6 null
We’ve now skipped the first 3 numbers and read just the next 3 numbers that we subsequently wrote to the stream. Pravega’s client API offers StreamCuts, Positions and EventPointers for advancing through streams. A StreamCut advances an entire reader group to a specific position across the segments in a stream. StreamCuts can be saved off and used later.
With a 2-second timeout on readNextEvent() in the above example, we did output one null, because unreadBytes() is a lagging metric. But now, should an unexpected timeout occur mid-stream, our loop won’t terminate until we’re certain we’ve reached the end of the stream. The above while loop is robust, even if we unnecessarily retry a few times due to lag in the metric. Otherwise, we’re simplifying our read loops in this article by taking advantage of the facts that our streams aren’t continuous and our standalone server isn’t under load.
There are many ways to control your read loop. For example, in our Boomi Connector, we read time- and count-based micro-batches to be fed into Boomi pipelines. The Boomi Connector read loop shows the importance of handling ReinitializationRequiredException and TruncatedDataException in long-running applications or reusable integrations.
Overviewing multi-segment streams that act less like files
Besides single-segment streams, streams can have many parallel segments, and the number of those segments can change over time, where the successor and predecessor relation between segments is preserved across time. While this increases the parallelism of streams, it also introduces a semantic of non-sequential and semi-sequential reads, which applications must consider as they compose their solutions with Pravega.
Exploring stream parallelism further will help us to conceive of how to compose our applications with Pravega. We will look first at placing writes across parallel segments randomly and then deterministically by routing keys.
To do this, we’ll need to create a new parallel-numbers stream that has more than 1 segment, let’s say, 5:
Non-sequential writes and reads on a multi-segment stream
If we again write successive integers to this stream of 5 fixed segments, we will find that they aren’t necessarily read back in order.
Outputs will be non-deterministic, for example:
6 1 4 5 2 3
Semi-sequential writes and reads preserving order with routing keys
For unrelated events, these kinds of out-of-order reads are acceptable, and the added stream parallelism allows us to operate at higher throughput rates when using multiple writers and readers.
Often, however, you’ll need to preserve the order of related events, and this is done in Pravega, as in other systems, with the use of per-event routing keys, where those events that share the same routing keys will be delivered to readers in the order they were acknowledged to the writers by the segment stores.
Let’s consider an example where we want to preserve the order of several independent series of events. In this last example with EventStreamClientFactory, we’ll use the decades of the number line, writing the numbers of each decade in order along with their respective routing keys of “ones,” “tens,” “twenties,” and so on:
The “ones” (0-9), “tens” (10-19) and “twenties” (20-29) are written to our parallel-decades stream. Since we have 3 sequences to 5 segments, each decade sequence is potentially in its own segment.
When we read this back, the values of each decade will be in order, but the sequences may be interleaved, and the lower decades won’t necessarily come first:
For me, this outputs:
10 0 20 11 1 21 12 2 22 13 3 23 14 4 24 15 5 25 16 6 26 17 7 27 18 8 28 19 9 29
As we can see, the decades are interspersed, but they remain in order with respect to themselves. Notice how Pravega doesn’t store routing keys on its own, because it treats user data very transparently. To preserve routing keys, simply include them in your events, and consider using a JSON or Avro serializer.
Batch client API overview
When reading events, EventStreamReader preserves the successor-predecessor relationship between segments, in that a successor segment is read in its entirety before any subsequent segments are read. For some applications, such as search, this constraint is overly restrictive in terms of performance. The batch API frees you of this constraint and allows you to read segments in parallel irrespective of which segments succeed other segments.
While streams are expected to use auto-scaling policies, applications can also manually scale their streams using the Controller API. For the sake of brevity, instead of waiting for a stream to auto-scale, let’s set up an example where we manually scale the stream, causing the stream to have predecessor and successor segments, and then check how the Batch API allows us to process all segments in parallel, rather than waiting for predecessor segments to finish processing before moving on to successor segments.
Let’s create a single-segment stream and write to it as before:
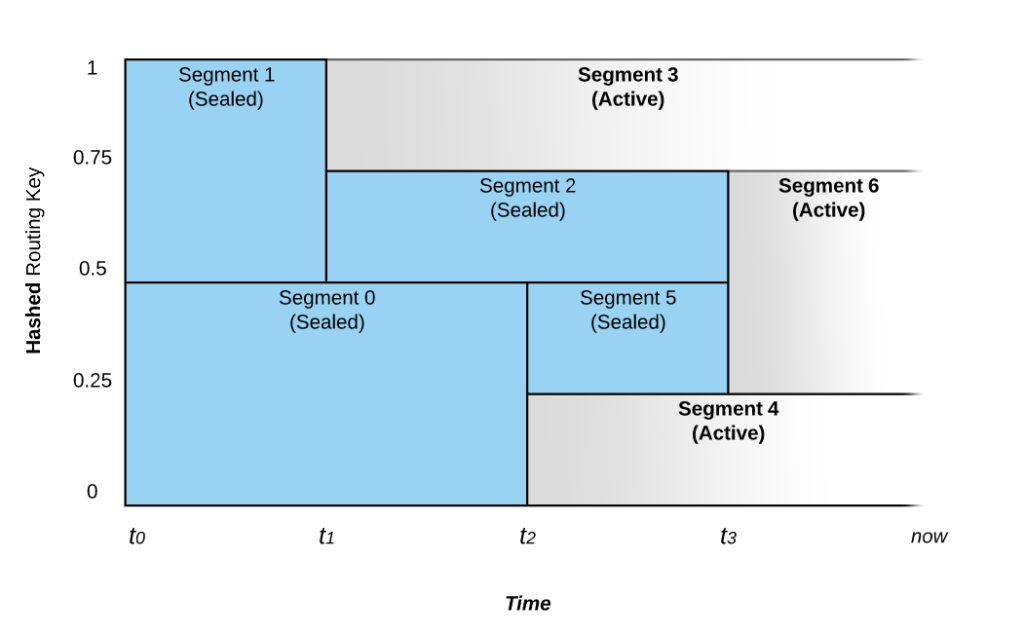
Now that we have an ordinal sequence in a single segment, let’s scale to two segments and write some more. In order to scale our segments, we need to understand that a segment is defined by a routing key range. A single-segment stream has one key range that is always 0.0 – 1.0. Routing keys are hashed to a decimal between 0 and 1, and writes are assigned to segments thereby (Fig. 2). To split our stream into two segments, we need to define two key ranges that divide the one key range, such as 0.0 – 0.5 and 0.5 – 1.0. We then use the Controller API to command our stream to undergo a scaling operation with the two new key ranges. We first retrieve the ID of the segment we want to seal and scale:
Output:
Number of segments: 1 Segment ID to scale: 0
Now that we’ve split our one key range into 2 key ranges, we have 2 segments on our stream after the 1st segment. When the scaleStream future completes, we will know if the scaling operation succeeded, and we will be able to write to our once serial, now parallel stream! Since our stream becomes unordered anyway now that it has more than 1 segment, let’s take advantage of that and write unordered in parallel:
If you’re fluent in Java, you may have noticed that ExecutorServiceHelpers and Futures are new. Pravega is chock-full of hidden gems with respect to API helpers and testing utilities.
Our stream is now composed of a single segment with ordered 1,2,3 followed by two segments with unordered 4 – 9, or {S1} -> {S2, S3}. When reading from such a stream under normal circumstances, a reader group will exhaust S1 before moving on to read from S2 and S3. The batch API will allow us to ignore the ordering of segments and process them all at once. The batch client presently hands out iterators, so let’s use this Java hack to transform iterators to streams (since I’m assuming Java 8):
First we’ll use BatchClientFactory to collect all segment ranges into a set so we can use parallelStream() to simulate shipping them off to workers for event processing:
Example output:
Segment ID: 0 Segment ID: 4294967298 7 5 4 1 2 3 Segment ID: 4294967297 6 8 9
Byte stream client API overview
The last thing we’ll look at is Pravega’s byte stream client. Byte streams are restricted to single-segment streams, but, unlike event streams, there is no event framing, so a reader cannot distinguish separate writes for you, and, if needed, you must do so by convention or by protocol in a layer above the reader. The byte stream client implements OutputStream, InputStream and NIO channels, allowing easy integration with Java. Let’s look at a simple example using ByteStreamClientFactory:
In this example, we used ByteStreamWriter and ByteStreamReader as the underlying OutputStream and InputStream for Java 1.0’s DataOutputStream and DataInputStream, respectively. One thing to know about ByteStreamReader is that, unlike EventStreamReader, it blocks forever on read and doesn’t time out.
Things to know not covered here
Pravega provides an additional revisioned stream client as well as Flink Connectors that expose Flink APIs over the event stream and batch clients. We will cover these in more detail in future articles. RevisionedStreamClient uses optimistic locking to provide strong consistency across writers, ensuring all writers have full knowledge of all stream contents as they issue writes in coordination with distributed processing. Lastly, our Flink Connectors provide end-to-end exactly once across pipelines of writers and readers, seamless integration with checkpoints and savepoints, and Table API with support for both batch and stream processing. Pravega’s 0.8 release introduces a new Key Value Table client built atop segments and state synchronizers.
Many advanced features of EventStreamClientFactory’s writers and readers have not been overviewed here but will get special attention in future articles. Some of these capabilities include automatic checkpoints, checkpoints used for exactly once processing, watermarks for time-oriented processing, writing with atomic transactions, and more.
Cleaning up after ourselves
As stated above, we should practice good hygiene and clean up after ourselves by deleting our reader groups, our streams and our scope (streams must be sealed, and scopes must be empty, to be deleted):
Conclusion
Understanding the fundamental aspects of streams as outlined above and their sequential, non-sequential and semi-sequential nature is all you need to compose applications with Pravega. Of course, Pravega has several more client interfaces and many advanced features, and we’ve only scratched the surface. But you’ve just learned the basics, and you’re ready to start building apps!
Final review
We’ve skimmed the surface area of Pravega’s client APIs, configuring streams, ordering writes in segments, creating reader groups and instantiating EventStreamWriters and EventStreamReaders.
We’ve seen how streams have varying semantics related to ordered and unordered writes and reads, depending on whether writes and reads happen within the same segment or across segments.
BatchClientFactory provides direct access to segments and, for the sake of raw performance, omits the successor ordering of segments in time across a stream.
The ByteStreamClientFactory APIs provide implementations of InputStream, OutputStream and NIO channels for working directly with the bytes in single-segment streams.
The basics covered here prepare an individual to think about how to decompose their problems according to the semantics provided by Pravega and how to begin composing solutions to those problems.
Get the code
Code for the above examples is available on GitHub in the form of easily executed JUnit tests:
https://github.com/pravega/blog-samples/tree/master/pravega-client-api-101
Acknowledgements
Special thanks belong to Flavio Junqueira, Sandeep Shridhar, Claudio Fahey, Ashish Batwara, and Tom Kaitchuck for their feedback, corrections and valuable insights. Thanks especially to the Pravega team as a whole for building such an awesome product and to you, the reader, for your patience in getting to this point and for all the solutions you’ll build on top of Pravega!